




































الباحثة/ ليديا أمير عدلي قسطندي
باحثة متخصصة في العلوم السياسية الرقمية بالجامعة المصرية الروسية
المقدمة:
تُعدّ لغات إفريقيا صوتًا مُهملاً في عصر الذكاء الاصطناعي؛ حيث تواجه القارة الإفريقية تحديًا كبيرًا يتمثل في غياب توثيق لغاتها المختلفة عن تقنيات الذكاء الاصطناعي المتقدمة؛ حيث تطغى اللغات العالمية، كالإنجليزية والفرنسية، على النماذج اللغوية، مما يُقيِّد وصول ملايين الأفارقة إلى خدمات رقمية تتماشى مع تراثهم اللغوي والثقافي.
هذا النقص ليس مجرد عائق تقني، بل يمتد إلى أبعاد ثقافية تتصل بالهوية والتراث اللغوي، وأبعاد سياسية تتعلق بتمثيل المجتمعات الإفريقية في الفضاء الرقمي؛ إذ يسهم استبعاد اللغات المحلية في تعميق التهميش وإضعاف التمكين الاجتماعي.
خلال الآونة الأخيرة، برزت مبادرات طموحة تسعى لسدّ هذه الفجوة من خلال مشاريع تهدف إلى دمج اللغات الإفريقية في تقنيات الذكاء الاصطناعي، لتعزيز الوصول إلى الخدمات الرقمية ودعم الابتكار المحلي.
يبرز من بين هذه المبادرات مشروع “أفريكان نيكست فويسز”، الذي يحمل إمكانيات ثقافية للحفاظ على التراث اللغوي، وبُعدًا سياسيًّا يُعزِّز حضور إفريقيا في الاقتصاد الرقمي العالمي، مع آثار اقتصادية مستقبلية تدعم النمو والتنمية المستدامة.
أولاً: واقع تهميش اللغات الإفريقية
تُعدّ إفريقيا من أكثر القارات تنوعًا لغويًّا؛ إذ تضم أكثر من ألفي لغة حية، إلا أن تمثيل هذه اللغات في تطبيقات الذكاء الاصطناعي لا يزال محدودًا للغاية. فعلى سبيل المثال، لا تتوافر سوى نحو 49 لغة إفريقية على منصات الترجمة الرقمية الشائعة مثل جوجل ترانسليت([1])، فيما يواجه 88% من اللغات الإفريقية حالة من التهميش الشديد أو الإهمال في مجالات اللغويات الحاسوبية.
يؤدي هذا التفاوت في تمثيل اللغات الرقمية إلى تعزيز الفجوة الثقافية والمعرفية بين المتحدثين باللغات الإفريقية واللغات العالمية الأكثر انتشارًا، ويضع اللغات الأقل دعمًا في خطر الانقراض الرقمي.
التطبيقات العملية للذكاء الاصطناعي، مثل منصات الترجمة، المساعدات الرقمية الذكية شات جي بي تي، وأدوات تحليل النصوص وغيرهم، غالبًا ما تُركّز على اللغات ذات الموارد الوفيرة، ما يُعزّز من سيطرة اللغات المؤسسية ويُقلّل من فرص دمج اللغات المحلية.
تعود أسباب هذا التهميش إلى عدة عوامل؛ من أبرزها: الإرث الاستعماري، وندرة البيانات الرقمية لهذه اللغات، بجانب قلة الدعم البحثي والتقني، وتفاوت النظرة المجتمعية والمؤسسية لأهمية اللغات المحلية. كما أن عدم وجود أُطُر تنظيمية وسياسات واضحة لحماية وتمكين اللغات الإفريقية في الفضاء الرقمي يزيد من تعقيد جهود دَمْجها في تطبيقات الذكاء الاصطناعي الحديث.
ثانيًا: نموذج بناء قواعد صوتية للغات الإفريقية
شهدت الأشهر الماضية تزايدًا ملحوظًا في الاهتمام بتطوير تقنيات الذكاء الاصطناعي القادرة على التعامل مع اللغات الإفريقية، التي طالما وُصِفَتْ بأنها “لغات قليلة الموارد”؛ نظرًا لندرة البيانات المتوفرة لها مقارنة باللغات العالمية المهيمنة.
بحلول يوليو/ تموز 2025م، نُشر بحث بعنوان “بيانات صوتية مُصطنعة للتعرّف التلقائي على الكلام في اللغات الإفريقية”([2])، طرح فيه الباحثون مقاربةً مبتكرة تقوم على توليد بيانات صوتية صناعية اعتمادًا على النصوص المُنتَجة بواسطة النماذج اللغوية الكبيرة، ومِن ثَم تحويلها إلى تسجيلات صوتية عبر تقنيات تحويل النص إلى كلام “تي تي إس”.
الهدف من هذا التوجه كان سد الفجوة الأولية في نقص الموارد، وتوفير قاعدة أولية لتدريب أنظمة -حتى وإن لم تكن طبيعية بالكامل- للتعرف الآلي على الكلام التي تعرف بي “ايه ار اس”. ثم انتقلت المنهجية بعد ذلك إلى مرحلة أوسع وأكثر طموحًا، متجاوزًا مرحلة البيانات الصناعية، لبناء قاعدة بيانات صوتية طبيعية شاملة.
وهنا يبرز مشروع “أفريكان نيكست فويسز”([3])؛ باعتباره مبادرة قارية تهدف إلى دمج اللغات الإفريقية في تقنيات الذكاء الاصطناعي؛ من خلال إنشاء أكبر بنية تحتية لغوية رقمية -أي قاعدة بيانات-، تسد فجوة التمثيل، وتدعم الهوية الثقافية والاقتصاد الرقمي في القارة.
كما برهنت التقارير المنشورة في “مجلة نتشير” بتاريخ 29 يوليو/ تموز 2025م أن هذه القاعدة تضمنت نحو 9.000 ساعة من المحادثات البشرية باللغات الإفريقية في كينيا ونيجيريا وجنوب إفريقيا، لتغطي نحو 18 لغة ولهجة محلية، منها الكيكويو ودولو في كينيا، والهاوسا واليوروبا في نيجيريا، وإيزيزولو وتسيفيندا في جنوب إفريقيا، وهي لغات يتحدث بها ملايين الأشخاص([4]).
جُمعت التسجيلات في سياقات حياتية يومية، مثل الصحة والتعليم والزراعة؛ لضمان واقعية التفاعل اللغوي، ثم خضعت لعمليات نَسْخ دقيقة وتعليقات “ميتاداتية” تتعلق بالسياق، اللهجة، جنس وهوية المتحدثين العمرية. مثلت هذه الخطوات نقلة نوعية؛ إذ وفَّرت للنماذج بيانات أصيلة تُمكِّنها من فهم الخصائص الطبيعية للغات الإفريقية بعيدًا عن القيود المصطنعة.
لم يكن المشروع وليد اللحظة، بل جاء تتويجًا لمراحل تحضيرية وتجارب سابقة. فقد شهدت كينيا أول ورشة عمل متعلقة بالمشروع في 29 أغسطس 2024م بجامعة ماسينو في كيسومو، والتي شكلت نقطة الانطلاق العملية لجمع البيانات الميدانية، ضمن إطار مشروع أكبر يسمى “كين كروبوس”.([5])
وهو شبكة تعاونية تضم عدة جامعات ومؤسسات بحثية كينية([6])، تهدف إلى تعزيز البحث اللغوي وجمع البيانات الصوتية لدعم تقنيات الذكاء الاصطناعي المعتمدة على اللغات الإفريقية بدعم من مؤسسة بيل وميليندا غيتس بقيمة 2.2 مليون دولار لمدة عام، وقد ركز هذا المشروع التجريبي على جمع بيانات نصية وصوتية من خمس لغات كينية رئيسية هي: الدهولوا، الكيكويو، السومالي، الكالينجي([7]) والماساي، بهدف اختبار منهجيات جمع البيانات وضمان موثوقية التسجيلات.
بالرغم من أن المشروع بدأ في كينيا، إلا أن جَمْع البيانات الصوتية في نيجيريا وجنوب إفريقيا تم بشكل متوازٍ، مما يعكس التوسع الجغرافي والتنوع اللغوي للمشروع.
في جنوب إفريقيا، يتواصل العمل ضمن هذا المشروع من خلال مجموعة علوم البيانات من أجل التأثير الاجتماعي DSFSI( ([8]في جامعة بريتوريا؛ حيث يجري التركيز على تطوير موارد رقمية لسبع لغات محلية أساسية هي: الإيزيزولو، الإيسيكوسا، السيسوتو، السيتسوانا، السيبيدي، الإيسينديبيلي، والتشيفيندا.
إلى جانب المبادرات القارية، تعمل نيجيريا أيضًا على مشاريع محلية مهمة في مجال الذكاء الاصطناعي اللغوي. من أبرز هذه المشاريع إطلاق مجموعة بيانات “NaijaVoices”، وهي قاعدة بيانات ضخمة تضم ما يقارب 1800 ساعة من النصوص الصوتية، وأكثر من 5000 متحدث بثلاث لغات رئيسية هي: الإيجبو، الهاوسا، واليوروبا. ورغم أنها تُصنَّف كمبادرة محلية([9])، إلا أنها تُمثّل خطوة إستراتيجية يمكن أن تُشكّل لاحقًا جزءًا من مشروع القاري “أفريكان نيكست فويسز”.
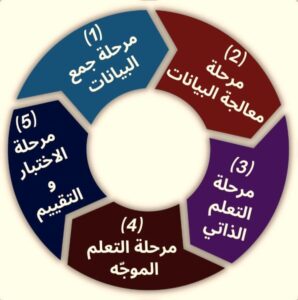
ومن الناحية التقنية، وفقًا للممارسات الديناميكية في تطوير نماذج التعرُّف على الكلام. اعتمد المشروع على منهجية تعلم الآلة، وهي عملية “تعليم” الكمبيوتر من خلال تغذيته بكمية ضخمة من الأمثلة الواقعية حتى يستطيع التعرف على أنماط الكلام وتوقعها. هنا لعبت قاعدة البيانات الصوتية –المكوَّنة من تسعة آلاف ساعة بـ18 لغة– دور المادة الخام التي لا يمكن للنماذج أن تتعلم من دونها([10]).
في البداية يمر الذكاء الاصطناعي بمرحلة التعلم الذاتي؛ حيث يستخلص خصائص عامة للصوت البشري، مثل النطق والوقفات والإيقاع. -أي بدون تسمية-، ثم تأتي مرحلة التعلم الموجّه؛ حيث يُربط كل مقطع صوتي بالنص المكتوب المقابل له -في وجود تسمية-، ليصبح النظام قادرًا على تحويل أيّ كلام منطوق إلى نص بدقة عالية. مع تطبيق أساليب لتقوية التوازن في البيانات؛ بحيث لا يطغى صوت أو لهجة على أخرى استُخدمت في ذلك تقنيات متقدمة مثل([11]) “ويسبير” و”واف توفيك”، والنتيجة النهائية كانت تحسينًا ملحوظًا في قدرة النماذج على التعرف على الكلام وتقليل نسبة الخطأ، ما فتح الباب أمام تطبيقات عملية واسعة تشمل المساعدات الصوتية المحلية، والتطبيقات الطبية والتعليمية، وصولًا إلى تعزيز العدالة الرقمية واللغوية داخل القارة الإفريقية.
شكل(1) مراحل بناء نموذج التعلم الآلي للتعرف على الكلام باللغة الإفريقية
يمكن القول: إن مشروع بناء القواعد الصوتية للغات الإفريقية يوفر بيانات أصيلة قد تُمكِّن النماذج من فهم اللغات بشكل دقيق. هذا التوظيف له أبعاد متعددة؛ فهي تعزّز الهوية والثقافة الإفريقية، وتترك أثرًا سياسيًّا وإستراتيجيًّا، وتفتح آفاقًا لفرص اقتصادية جديدة
ثالثًا: دور النموذج في الثقافة الإفريقية
يسعى النموذج إلى إعادة التوازن اللغوي داخل الذكاء الاصطناعي، من خلال قاعدة البيانات التي تعالج نقص الموارد اللغوية، ويتيح دمجها في التطبيقات الذكية لتصبح جزءًا من الابتكار التكنولوجي العالمي، ما يخلق مساحة متكافئة للغات الأقل انتشارًا جنبًا إلى جنب مع اللغات المهيمنة.
ويعمل على تعزيز الجانب الثقافي من القارة، وتتجلى هذه الأبعاد الثقافية فيما يلي:
1-الذكاء الاصطناعي أداة لتحقيق المساواة الثقافية الرقمية
قد تمثل منهجية المشروع منظورًا مختلفًا في توظيف الذكاء الاصطناعي لتعزيز الحضور الثقافي الإفريقي؛ إذ يوفّر قاعدة بيانات لغوية غير مسبوقة تُمكِّن القارة من الحفاظ على تنوعها اللغوي، وإعادة دمج لغاتها في الفضاء الرقمي العالمي.
غير أن أهميته لا تقتصر على البعد التقني فحسب؛ إذ إن هذه الخطوة تُمثّل انتقالاً إستراتيجيًّا لإفريقيا من موقع التابع الذي يعتمد على أنظمة تُطوَّر في مراكز القوة العالمية –مثل الصين والولايات المتحدة– إلى فاعلٍ مُنْتِج يُسْهِم في صياغة مشهد الذكاء الاصطناعي نفسه. فبينما تُظهر التجارب مع النماذج اللغوية الكبرى أنها ما تزال عاجزة عن فَهْم السياقات الثقافية المتنوعة، وتكشف عن تحيزات تُعزّز عدم المساواة.
تأتي هذه المنهجية لتعيد تعريف الذكاء الاصطناعي كمساحة للعدالة الثقافية، من خلال إدخال لغات مُهمَّشة تاريخيًّا إلى قلب النظام التكنولوجي العالمي وإشراك المجتمعات المحلية في جمع البيانات وتقييم النماذج، يتم ضمان أن التكنولوجيا تعكس الواقع اللغوي والثقافي لكل مجتمع، وتجنّب فرض نماذج جاهزة غير مناسبة؛ أي نماذج القوي الكبرى والنماذج الصناعية. وينتج عن ذلك تعزيز التمثيل الرقمي للغات الإفريقية، وحماية اللغات الأقل انتشارًا من الاندثار، وتمكين المتحدثين من الوصول إلى أدوات رقمية متقدمة بلغاتهم الأم، ما يخلق فرصًا متكافئة في التعليم، الثقافة، والتواصل الرقمي، وهذا يضمن أن المتحدثين باللغات الإفريقية لن يكونوا مجرد مستقبلين للمعرفة، بل مشاركين فاعلين بلغاتهم الأصلية في ظل العولمة الراهنة.
2-الذكاء الاصطناعي كأداة لتعزيز الهوية الثقافية الإفريقية
أصبح استخدام الذكاء الاصطناعي وسيلة توثيقية لحفظ الذاكرة الثقافية للأمم الإفريقية. فاللغات الإفريقية غالبًا ما ارتبطت بالتقاليد الشفوية؛ حيث تنتقل الحكايات والأساطير والأمثال الشعبية عبر الأجيال بالكلام المباشر. ومع آثار الاستعمار الغربي، وما ترتب عليه من تهميش لهذه اللغات، باتت مُهدّدة بخطر النسيان والتحريف مع مرور الزمن.
من هنا، جاء دور الذكاء الاصطناعي ليُحوِّل هذه الذاكرة الشفوية إلى أرشيفات رقمية حيَّة. فمن خلال تقنيات معالجة أصبح بالإمكان جمع النصوص والأساطير الشعبية وتحويلها إلى تقنيات معالجة مثل “إن بي إل”، يسهل الرجوع إليها، ما يضمن بقاء هذه الموروثات حية ومتاحة للأجيال المقبلة.
إضافة إلى ذلك، يُتيح تدريب نماذج الذكاء الاصطناعي على لغات مثل السواحيلية والهوسا تطوير تطبيقات قادرة على إنتاج محتوى أصيل -كالقصص والأمثال والشعر- باللغات المحلية. هذا الاستخدام لا يحافظ على اللغة فقط، بل يمنحها مكانتها كرمز حضاري يُعزّز الفخر بالهوية الثقافية، ويتيح للشباب الإفريقي التفاعل مع ثقافتهم بطرق معاصرة، سواء عبر التطبيقات التعليمية أو المنصات الفنية والترفيه الرقمي.
دعمت الأدبيات العلمية هذا الاتجاه؛ إلا أن الذكاء الاصطناعي حسَّن بشكل ملحوظ من حفظ اللغة من خلال النسخ الآلي للتقاليد الشفوية، الترجمة العصبية، والأرشفة الرقمية([12]). كما أوضحت أن هذه التقنيات تُسهم في إنشاء أدوات تعلم تفاعلية وتفتح آفاقًا للإحياء المستدام للغات الإفريقية الأصلية، بما يعزز مرونتها اللغوية عالميًّا.
من خلال ما سبق، أصبح الذكاء الاصطناعي أداة إستراتيجية لإحياء اللغات المهمشة وتعزيز العدالة والهوية الثقافية الإفريقية في عصر رقمي سريع التغير.
رابعًا: أهمية النموذج السياسية والاستراتيجية
لم يَعُد الاهتمام باللغات الإفريقية مسألة ثقافية أو تعليمية فقط، بل أصبح جزءًا من النقاشات الكبرى حول السيادة الرقمية، الاستقلال التكنولوجي، والمكانة الدولية للقارة.
إن مشاريع بناء قواعد بيانات صوتية للغات الإفريقية تحمل في جوهرها بُعدًا سياسيًّا وإستراتيجيًّا عميقًا، لأنها تمسّ مباشرة قضايا الأمن القومي، النفوذ الدولي، والتحرُّر من التبعية للخارج.
في سياق 2025م، أعلن الاتحاد الإفريقي الذكاء الاصطناعي كأولوية إستراتيجية ضمن أجندة 2063([13])، تطمح إستراتيجية الاتحاد الإفريقي للتحول الرقمي 2020-2030م إلى توفير وصول رقمي شامل. مع التركيز على دمج اللغات المحلية لتعزيز النمو الاقتصادي، وتعزيز التعاون بين الدول الأعضاء، مما يجعل مشاريع مثل “أفريكان نيكست فويسز” جزءًا من خطة قارية أوسع للسيطرة على البنية التحتية اللغوية.
وتتمثل أهمية النموذج السياسية والإستراتيجية فيما يلي:
1-الأمن اللغوي وتعزيز السيادة الرقمية الإفريقية:
تمثل المنهجية أكثر من مجرد قاعدة بيانات صوتية؛ فهو يرتبط مباشرة بمفهوم الأمن اللغوي، الذي يُعدّ جزءًا من الأمن القومي. ويعني ذلك حماية اللغات الإفريقية المحلية وبياناتها الرقمية من أيّ استغلال خارجي، سواء مِن قِبَل شركات أجنبية أو قوى دولية؛ بحيث تظل اللغة أداة للهوية والثقافة، لا وسيلة للهيمنة أو المراقبة.
إذ إن امتلاك البيانات الصوتية الخاصة باللغات الإفريقية مِن قِبَل جهات خارجية قد يُحوِّلها إلى أداة للتأثير السياسي أو المراقبة، مما يُهدِّد سيادة الدول الإفريقية وقدرتها على التحكم في معلوماتها الداخلية.
هذا الطرح يتماشى مع نقاشات حالية داخل الاتحاد الإفريقي حول السيادة الرقمية، كما توضحه تقارير بحثية([14])، التي تؤكد أن إفريقيا تُواجه تحديًا مزدوجًا يتمثل في ضرورة جذب الاستثمارات لبناء مراكز البيانات من جهة، والحفاظ على استقلالية التحكم بالبيانات والسيادة عليها من جهة أخرى. وهذا ما يدعمه المشروع في تحقيق السيادة الرقمية.
2-اللغة كقوة ناعمة رقمية في العلاقات الدولية
لا يقتصر المشروع على حماية الأمن القومي، بل قد يشمل أيضًا جهودًا لتعزيز استخدام اللغات الإفريقية في الفضاء الرقمي، كأداة للقوة الناعمة من خلال دمج اللغات الإفريقية في تقنيات الذكاء الاصطناعي الحديثة، مما يُعزّز نفوذ الدول الإفريقية على الساحة الدولية، ويتيح لها فرصًا إستراتيجية للتفاعل مع شركات عالمية.
وبحلول 5 أغسطس/آب 2025م، أعلنت شركة “أورانج” الفرنسية عن خطط لاستخدام نماذج الذكاء الاصطناعي الحديثة من “OpenAI” لدعم وتعزيز اللغات الإفريقية([15])، التي كانت تاريخيًّا مُهمَّشة في تطور الذكاء الاصطناعي بسبب نقص البيانات والموارد الحاسوبية.
تُعتبر هذه الشراكة خطوة إستراتيجية مِن قِبَل فرنسا لتعزيز علاقاتها مع الدول الإفريقية؛ حيث تُظهر التزامًا بتطوير التكنولوجيا الرقمية في القارة. من خلال توفير أدوات الذكاء الاصطناعي بلغات محلية، تُسهم فرنسا في تعزيز التمكين الرقمي للمجتمعات الإفريقية، مما يُحسِّن صورتها كداعم للتنمية المستدامة في القارة.
تُظهر هذه الشراكة كيف يمكن للمشاريع التكنولوجية أن تُصبح أدوات دبلوماسية ناعمة؛ حيث تُسهم في بناء علاقات إستراتيجية بين الدول والشركات.
من خلال تمكين اللغات الإفريقية في الذكاء الاصطناعي، تُعزز فرنسا من مكانتها كداعم رئيسي للتنمية الرقمية في إفريقيا. علاوة على ذلك، يُمكن أن تُسهم هذه المبادرات في تعزيز التعاون الإقليمي بين الدول الإفريقية؛ حيث تُشجع على تبادل المعرفة والخبرات في مجال التكنولوجيا الرقمية.
خامسًا: الآثار المحتملة للاقتصاد الرقمي الإفريقي
1-قد يسهم النموذج في تحويل إفريقيا من مجرد مستهلك للتقنيات إلى مُنْتِج ومُصدِّر للبيانات والتطبيقات الرقمية. من خلال قاعدة البيانات الضخمة باللغات المحلية، أصبح بإمكان القارة توفير مادة أولية قوية لتدريب أنظمة الذكاء الاصطناعي وتحسين أدائها.
2-ما يُبرز المشروع أيضًا أهمية جذب بيئة استثمارية رقمية على مستوى القارة الإفريقية، من خلال دمج اللغات الإفريقية في تطبيقات الذكاء الاصطناعي الحديثة.
هذا الدمج يُمكِّن الشركات الناشئة والمطورين من تطوير حلول رقمية موجهة للمجتمعات المحلية بلغاتها الأم، ما يفتح فرصًا استثمارية جديدة لم تكن متاحة قبل وجود قواعد البيانات الصوتية الضخمة للمشروع.
على صعيد داعم، أعلنت شركة جوجل في يوليو 2024م عن إضافة 31 لغة إفريقية جديدة إلى خدمة “جوجل ترانسليت”، بما في ذلك لغات مثل وولوف، ديولا، وتمازيغت، وهو ما أتاح لما يقرب من 200 مليون متحدث التواصل بلغاتهم الأم على منصة عالمية([16]).
تُظهر هذه الخطوة كيف يمكن للاستثمارات الرقمية الاستفادة من توافر قواعد البيانات اللغوية؛ حيث توسّع قاعدة المستخدمين وتزيد الطلب على التطبيقات والخدمات الرقمية المخصصة لكل لغة وثقافة محلية.
3-قد يُعزّز المشروع فرص فتح أسواق جديدة وتعزيز الابتكار الاقتصادي([17]). فعلى سبيل المثال، يمكن لمنصات التجارة الإلكترونية أن تزدهر من خلال تقديم خدمات بلغات محلية مثل الكيكويو أو الهوسا، مما يُمكِّن الشركات الصغيرة ورُوّاد الأعمال من الوصول إلى قاعدة عملاء أوسع.
4-كما يُعالج المشروع تحدّي التكاليف المرتفعة لتطوير الذكاء الاصطناعي باللغات غير اللاتينية، التي تُعدّ حاليًّا أكثر تكلفة مقارنةً باللغات مثل الإنجليزية.
من خلال توفير بيانات صوتية جاهزة للذكاء الاصطناعي، يُقلل المشروع من هذه التكاليف، مما يُتيح فرصًا للابتكار في قطاعات مثل التجارة الإلكترونية والخدمات الرقمية.
هذا التحوُّل يُساهم في تعزيز الاقتصاد الرقمي الإفريقي؛ حيث تُشير التوقعات إلى أن الذكاء الاصطناعي يمكن أن يُضيف ما يصل إلى 2.9 تريليون دولار إلى الناتج المحلي الإجمالي العالمي([18])، من خلال مشاريع ومنهجيات مثل “أفريكان نيكست فويسز”.
وقد جمعت هذه المبادرات بين التكنولوجيا الحديثة وفرص الاستثمار الرقمي؛ حيث تساهم في تعزيز نشاط الاقتصاد الرقمي القاري بشكل ملموس. وإدماج اللغات المحلية في المنصات الرقمية يزيد شمولية الخدمات للمجتمعات، ويتيح للشركات المحلية والدولية فرص استهداف مستخدمين حقيقيين بلغاتهم الأم، ما يخلق فرصًا تجارية واقعية في السوق الرقمية.
سادسًا: الفجوات والتحديات المتوقعة
قد يمثل المشروع خطوة مهمة نحو دمج اللغات الإفريقية في الذكاء الاصطناعي، لكنّه يُواجه مجموعة من التحديات الجوهرية التي تؤثر على إمكانية تعميمه واستدامته، والتي يمكن تصنيفها كما يلي:
1-التحديات التقنية
أ- الفجوة الرقمية بين الدول الإفريقية
تتفاوت الدول الإفريقية بشكل كبير في مستوى تقدمها الرقمي، فبعض الدول مثل جنوب إفريقيا في الجنوب ونيجيريا في الغرب؛ حيث تحتل المرتبة العاشرة عالميًّا باستخدام 147 مليون شخص لوسائل التواصل الاجتماعي، وكينيا في الشرق تمتلك بنية تحتية رقمية متطورة نسبيًّا؛ تشمل الإنترنت عالي السرعة وأجهزة حديثة، بينما تواجه دول أخرى ضعف الشبكات، وانقطاع الكهرباء المتكرر، وصعوبة الوصول إلى أجهزة الحوسبة والهواتف مثل جنوب السودان والنيجر وإريتريا وغيرها؛ بسبب النزاعات وعدم الاستقرار السياسي والنظم الاستبدادية. هذا التفاوت يُعدّ عائقًا ضخمًا في تطبيق المشروع بشكل متكافئ. ويؤثر على إمكانية وصول جميع المجتمعات إلى هذه التكنولوجيا، مما قد يؤدي إلى تفاقم الفجوات الرقمية القائمة.
ب- التنوع اللغوي الهائل
تضم القارة الإفريقية أكثر من ألفي لغة حية كما قلنا، بالإضافة إلى عدد كبير من اللهجات المحلية المتنوعة، بعضها يتحدّث به مجموعات صغيرة جدًّا.
هذا التنوع اللغوي يجعل من الصعب جَمْع بيانات صوتية ممثلة بشكل متوازن لكل لغة ولهجة. كما يزيد التعقيد عند الحاجة لتطوير نماذج ذكاء اصطناعي قادرة على التعرُّف على هذه الاختلافات، ما قد يؤدي إلى تحيُّز النماذج تجاه اللغات الأكثر استخدامًا وترك لغات أخرى مهمشة.
ج- تفاوت جودة البيانات الصوتية
حتى مع جمع آلاف الساعات من التسجيلات الصوتية، قد تختلف جودة هذه البيانات بين المناطق والمجموعات اللغوية بسبب الضوضاء الخلفية أثناء التسجيل، اختلاف نطق الكلمات واللهجات المحلية، أو ضعف وضوح الصوت عند بعض المتحدثين، ما يقلل من دقة النماذج النهائية للذكاء الاصطناعي، ويؤثر على القدرة على تقديم خدمات صوتية فعّالة لكل المجتمعات الإفريقية.
د- عوائق جمع البيانات في الميدان
بسبب الانتشار الجغرافي الواسع لبعض اللغات، ووجود مناطق نائية أو متأثرة بالصراعات المحلية مثل دولة جنوب السودان؛ يصبح الوصول إلى المجتمعات صعبًا. كما أن بعض المجموعات قد تكون مُهمَّشة أو غير راغبة في المشاركة، أو يصعب على فِرَق البحث الوصول إليهم بأمان، ما يجعل إنشاء قاعدة بيانات متسقة وشاملة تحديًا كبيرًا.
2-التحديات الاقتصادية
أ. تكلفة التمويل والبنية التحتية
جمع البيانات الصوتية الطبيعية يتطلب استثمارات ضخمة في المعدات وفِرَق العمل المتخصصة، بالإضافة إلى الوقت الطويل اللازم لإتمام هذه المهام. هذه التكاليف العالية تجعل بعض الدول والمؤسسات غير قادرة على المشاركة الكاملة، ما يَحُدّ من شمولية قاعدة البيانات اللغوية، ويُؤثّر على تمثيل اللغات الإفريقية في الذكاء الاصطناعي. بالإضافة إلى ذلك، جزء كبير من تمويل هذه المشاريع ليس خاضعًا لرقابة محلية مباشرة، ففي عام 2024م، أشارت التقارير إلى أن أكثر من 90% من تدريب نماذج الذكاء الاصطناعي للغات الإفريقية يتم على بنى تحتية تقع خارج القارة([19])، مما يعكس ضعف بنية تحتية تمويلية.
ب- دور التمويل الدولي والشركات الكبرى
على سبيل المثال، ساهمت فرنسا في تمويل المشروع، ودمج بعض اللغات الإفريقية في منصات الذكاء الاصطناعي الحديثة عبر شراكة مع OpenAI، ما يعكس اهتمامًا عالميًّا بالتقنيات الإفريقية، لكنه يطرح تحديًا اقتصاديًّا يتمثل في اعتماد جزء كبير من البيانات على مؤسسات خارجية.
أقل من 5% من البيانات الصوتية تحت إدارة مؤسسات إفريقية، بينما تسيطر شركات عالمية كبرى على الجزء الأكبر، ما يقلل من استقلالية إفريقيا الرقمية، ويَحُدّ من العوائد الاقتصادية المباشرة للقارة.
3-التحديات التشريعية والقانونية
غياب إطار قانوني موحد
يُعدّ غياب إطار قانوني موحّد على المستوى القاري من أكبر العوائق أمام تنفيذ مشروع لغوي بهذا الحجم. فبينما يسعى المشروع إلى تحقيق شمولية تمتد عبر دول إفريقية متعددة، يظل تفاوت التشريعات الوطنية واختلاف الأُطُر التنظيمية المحلية عائقًا جوهريًّا أمام التطبيق العملي.
إذ تُواجه كل دولة منظومة قانونية وسياسات خاصة بإدارة البيانات والملكية الفكرية وحماية الخصوصية، ما يُؤدّي إلى تضارب في آليات التنفيذ، ويُعرقل إمكانية الوصول إلى نموذج متكامل ومتناسق. ويُبرز هذا التحدي الحاجة المُلِحّة إلى وضع إطار تشريعي قاري يضمن تنسيق الجهود، ويعزز قدرة المشروع على الاستدامة والتأثير الفعّال.
الخاتمة:
يُعتَبر مشروع دمج اللغات الإفريقية في أنظمة الذكاء الاصطناعي فرصة إستراتيجية متعددة الأبعاد، فهو يتيح للقارة تعزيز هويتها الثقافية من خلال الحفاظ على تنوعها اللغوي، ويدعم التنمية الاقتصادية عبر فتح آفاق للاستثمار الرقمي، وخلق فرص عمل نوعية، كما يُعزّز البعد السياسي من خلال توسيع السيادة الرقمية وقدرة الدول الإفريقية على التحكم في بياناتها ومعارفها.
في الوقت نفسه، لا يمكن تجاهل العوائق والتحديات الملازمة لهذا التوجُّه؛ إذ قد تتحول هذه المبادرات إلى أدوات لاستحواذ أو نفوذ غربي إذا لم تصحبها أُطُر تنظيمية قوية وإستراتيجيات واضحة، كما يواجه تنفيذ المشروع عقبات تقنية واقتصادية وقانونية، مثل التفاوت في البنية التحتية الرقمية، التنوع اللغوي الهائل، وتكاليف جمع وإدارة البيانات.
يعتبر نجاح توظيف الذكاء الاصطناعي في تحقيق هذه الأهداف معتمدًا على قدرة القارة على بناء أنظمة متوازنة تدمج اللغات المحلية بشكل فعّال، مع استثمار المعرفة والبيانات في حلول قابلة للتسويق محليًّا وإقليميًّا، ووضع سياسات تحفظ استقلالية القرار الرقمي.
……………………..
[1] Smartling. “Reviving Voices: How the African Languages Lab is Empowering Low-resource Languages with AI.” Smartling Blog, 2 Des 2024. https://www.smartling.com/blog/african-languages-lab-empowers-low-resource-languages-with-ai
[2] DeRenzi, Brian, Anna Dixon, Mohamed Aymane Farhi, and Christian Resch. “Synthetic Voice Data for Automatic Speech Recognition in African Languages.” arXiv, July 2025. https://arxiv.org/pdf/2507.17578.
[3] Sarah Wild. “AI models are neglecting African languages — scientists want to change that.” Nature, 29 july 2025. https://doi.org/10.1038/d41586-025-02292-5
[4] Fihlani, Pumza. 2025. “Lost in Translation – How Africa Is Trying to Close the AI Language Gap.” BBC News, September 4. https://www.bbc.com/news/articles/crkzgkkpx0lo
[5] Maseno University. “The African Next Voices Workshop.” Maseno University, August 29, 2024. https://www.maseno.ac.ke/african-next-voices-workshop.
[6] KenCorpus. 2024. “KenCorpus: Kenyan Languages Corpus.” KenCorpus Dataverse. https://share.google/o5no0wuChArsvEXtP.
[7] Digital Watch. “New Project Expands AI Access for African Languages.” Digital Watch, September 9, 2025. https://dig.watch/updates/new-project-expands-ai-access-for-african-languages.
[8] Marivate, Vukosi, et al. “Swivuriso: ZA-African Next Voices.” Data Science for Social Impact, University of Pretoria. Accessed September 12, 2025. https://www.dsfsi.co.za/za-african-next-voices/
[9] Emezue, Chris, et al. “The NaijaVoices Dataset: Cultivating Large-Scale, High-Quality, Culturally-Rich Speech Data for African Languages.” arXiv, May 26, 2025. https://arxiv.org/abs/2505.20564
[10] IBM. “What Is Machine Learning?” IBM Think. Accessed September 13, 2025. https://www.ibm.com/think/topics/machine-learning
[11] Chaitalisawant. “Building a Real-Time Speech-to-Text AI System Using Whisper & Wav2Vec2.” Medium, April 1, 2025. https://medium.com/@chaitalisawant22/building-a-real-time-speech-to-text-ai-system-using-whisper-wav2vec2-408cd5585e5f
[12] Midigo, Jackton Otieno. “AI-Powered Innovations for Documenting and Revitalizing African Languages.” Cultural Arts Research and Development 5, no. 2 (2025): 26–41. https://doi.org/10.55121/card.v5i2.517.
[13] African Union Commission. 2025. “Africa Declares AI a Strategic Priority as High-Level Dialogue Calls for Investment, Inclusion, and Innovation.” African Union Press Release, May 17, 2025. https://au.int/en/pressreleases/20250517/africa-declares-ai-strategic-priority-investment-inclusion-and-innovation.
[14] Banya, Roland Mwesigwa. “Africa’s Digital Sovereignty Trap: Breaking the Data Center Development Deadlock.” Planetary Politics, New America, 30 Jul 2025. https://www.newamerica.org/planetary-politics/briefs/africas-digital-sovereignty-trap/
[15] Mukherjee, Supantha. “Orange to Use OpenAI’s Latest Models to Work with African Languages.” Reuters, 5 Aug 2025. https://www.reuters.com/world/africa/orange-use-openais-latest-models-work-with-african-languages-2025-08-05/
[17] AI Competence. 2024. “African Languages in AI: Barriers with NLP.” Accessed September 14, 2025. https://aicompetence.org/african-languages-in-ai-barriers-with-nlp/
[18] International Development Research Centre (IDRC). 2024. “Call for Concept Notes: Socio-Economic Impacts of Artificial Intelligence in Africa.” Accessed September 14, 2025. https://idrc-crdi.ca/en/call-concept-notes-socio-economic-impacts-artificial-intelligence-africa
[19] After the Swahili AI Race: Africa’s Fight for Language Infrastructure Control.” Geopolitical Monitor, September 2025. https://www.geopoliticalmonitor.com/after-the-swahili-ai-race-africas-fight-for-language-infrastructure-control/






{kind=link}